

Sharpening insights in the eye of the data storm
Several years ago, a common refrain within cyber insurance was that the industry was held back by a lack of data. Today, that conversation has changed. You would be more likely to hear that the explosion of data available to this industry is so immense that the greatest challenge is sifting through that data and finding the signal within the noise.
In a recent podcast with Matthew Grant of Instech London, I tried to address some of the issues surrounding data when he asked how my perspectives on data had changed. And the landscape has changed. Insurance institutions are increasingly recognizing the need to sift through the noise surrounding data to find the right signal that drives claims. Critically, even when an institution finds that relevant signal, the hard work has only just begun in undertaking the quality assurance, the de-duplication, the synching to company names, the storage, the updates, the processing and the abstraction of the signal at the right level.
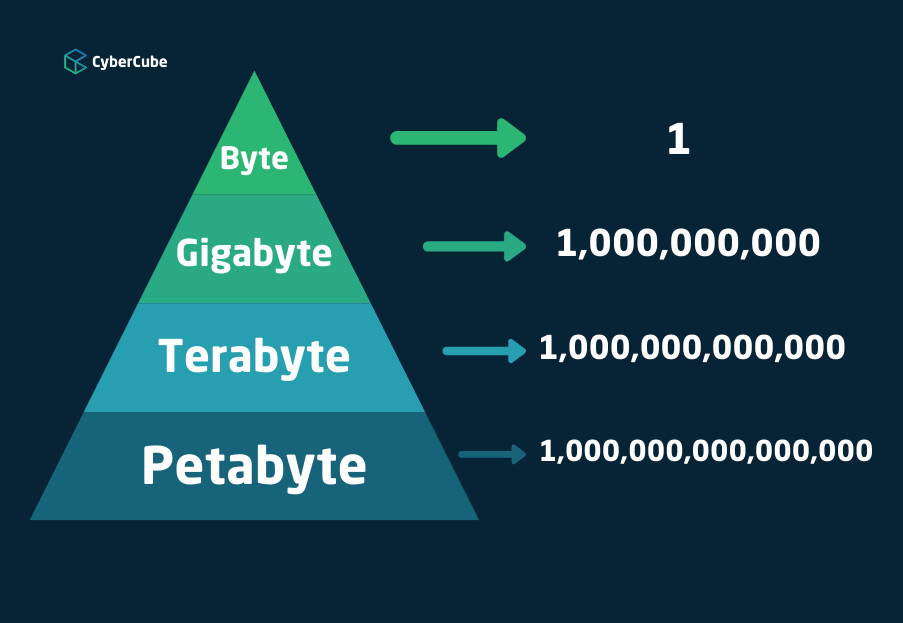
The volumes of data in cyber analytics are often at a Petabyte scale, which is a hard concept for many people to wrap their heads around. A good unit of measure for many of us (including many actuaries), would be the capacity of Microsoft Excel, which can handle up to 1-2 Gigabytes of data if you have a powerful laptop and the company’s latest software. For reference, a Gigabyte of data is approximately one billion bytes (1,000,000,000 bytes). That same actuary is now faced with a line of business where data vendors are processing Petabytes of data (1,000,000,000,000,000 bytes). That isn’t an incremental increase in data, it is literally one million times more data.
A core activity for CyberCube is not expanding the data we provide to our insurance clients but refining and reducing it. The reality is, our clients don’t just want more data, they want more insight. This requires synthesizing 999 out of every 1,000 bytes of data as we translate the Petabyte scale volume of raw data at our data partners to what is often a Terabyte scale ingestion process at CyberCube with usable company-level data. It requires synthesizing 999 out of every 1,000 bytes of data at that Terabyte scale to derive actionable insight at the Gigabyte scale. And ultimately, for our clients, it often comes down to a single byte that drives an insurance business decision: 0 or 1. Do I underwrite this risk or not?
CyberCube has screened more than 100 data partners and leverages data from dozens of data partners in our platform. We sift through that data, synthesize it at the right level of abstraction, and augment it with CyberCube's proprietary signals and data feedback loops from our clients to deliver the right data in the correct format in a way that requires advanced use of cloud-native technology.
New Application Programming Interface (APIs) are becoming critical to the development of insurance solutions because they allow the actuary, underwriter, or modeller to build technology platforms that can consume and share large volumes of data that are preprocessed at the right level of abstraction for insurance users to consume. This is where CyberCube comes in as a key analytic partner to the insurance industry. For many clients, they will consume our analytics through our easy-to-use and intuitive Software as a Services (SaaS) applications. For others, they need deeper access to our data and analytics layer through APIs, such as CyberCube’s recent announcement with SCOR.
In order for the insurance industry to capitalize on the enormous opportunities presented by cyber risk in the 21st Century, insurance institutions need access to data at a scale they may not have engaged with before. The question is no longer, do I have access to enough data but how do I manage the amount of data that I have access to and how do I use it to make a decision? Whether an insurer needs a single byte of data to support a decision (yes or no) or APIs into our platform to support their own more complex use cases, we are here to support the industry and take advantage of the opportunity in front of us all. Asking the right question in the first place is as important as the data you use to find the answer.

