
The capability for users to share documents between themselves is important in any software. It allows team members to collaborate more efficiently.
But what should a user collaboration service do? It is a service that should allow users to share objects, such as portfolios and analyses among themselves, and do it efficiently and easily.
Users can also create their own groups so that they may share an object with a set of people. You can think of those like email distribution lists.
This blog touches upon how we solved the issue of creating relationships between users and documents, while allowing for access control. Our product managers came up with requirements and, from an engineering standpoint, we wanted to build a reliable and scalable service.
Here’s a simple view of what sharing objects look like:
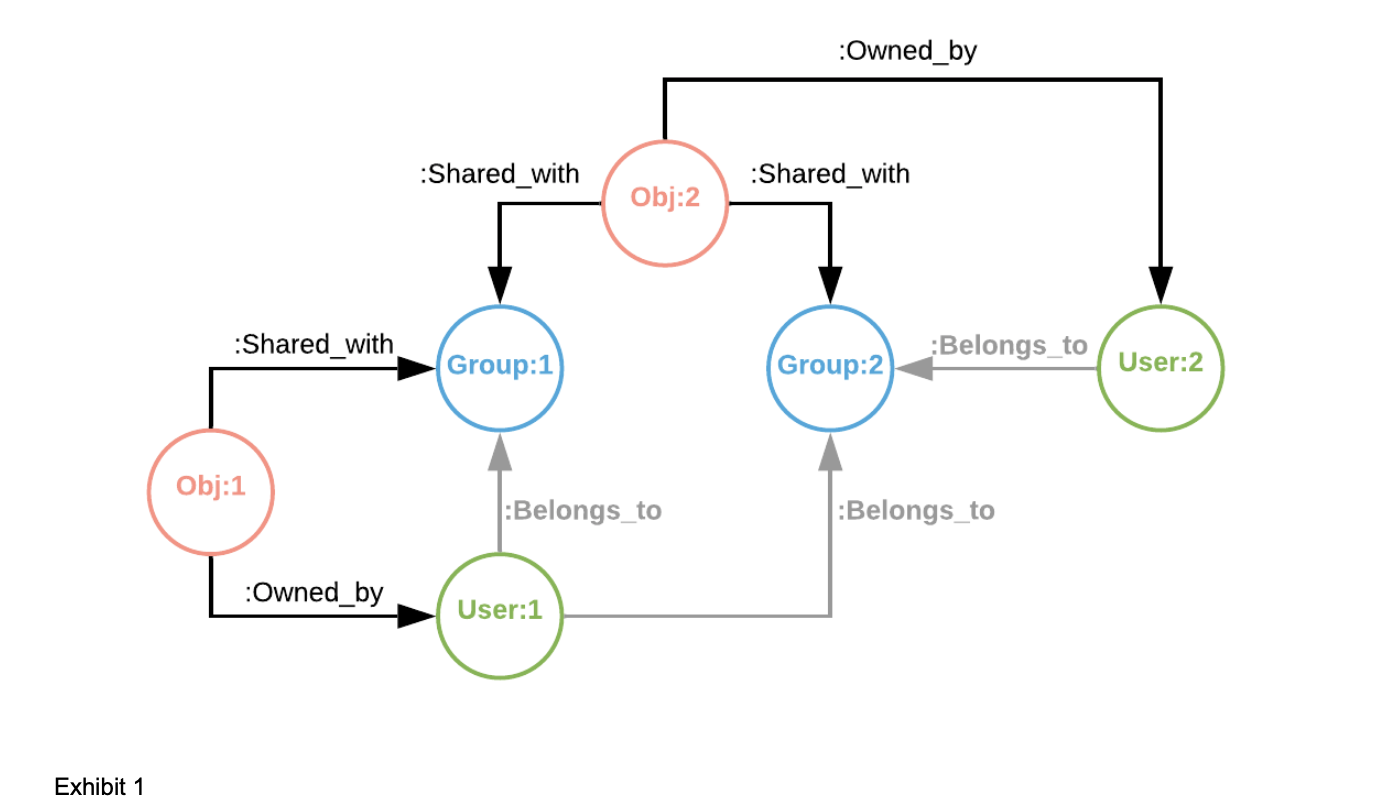
Essentially, entities are linked together. It’s something that we could have done with a relational database, but that would most likely have been somewhat clunky and overly complex. If you look at it carefully, you can see that it’s a graphical representation of a set of relationships. Therefore, we opted for a Graph Database instead.
The original thought was to use a graph database like Neo4J, simply because the query language (Cypher) is somewhat close to SQL and for someone who is not familiar with Graph Databases, the learning curve would not be very steep. As good as Neo4J is, we would have had to spin yet another EC2 instance (or potentially more), install the software, maintain the database, the instance, configure the VPC, figure out a way to connect securely to it, so on so forth.
It was apparent that AWS Neptune would be a better alternative. It’s part of AWS, is easy to configure and we can authenticate it via IAM.
Setting up Neptune
First, you need to create a database.
- Select the version you want, 1.0.4.1 R4, for example
- Name your cluster
- Pick a template (Production or Development & Testing)
- Select a size (default being db.r5.xlarge: 4 VCPU 32G RAM, EBS - 3500Mbps)
- You will then need to pick a VPC and a security group
Once you are done, you will have something that should like this:
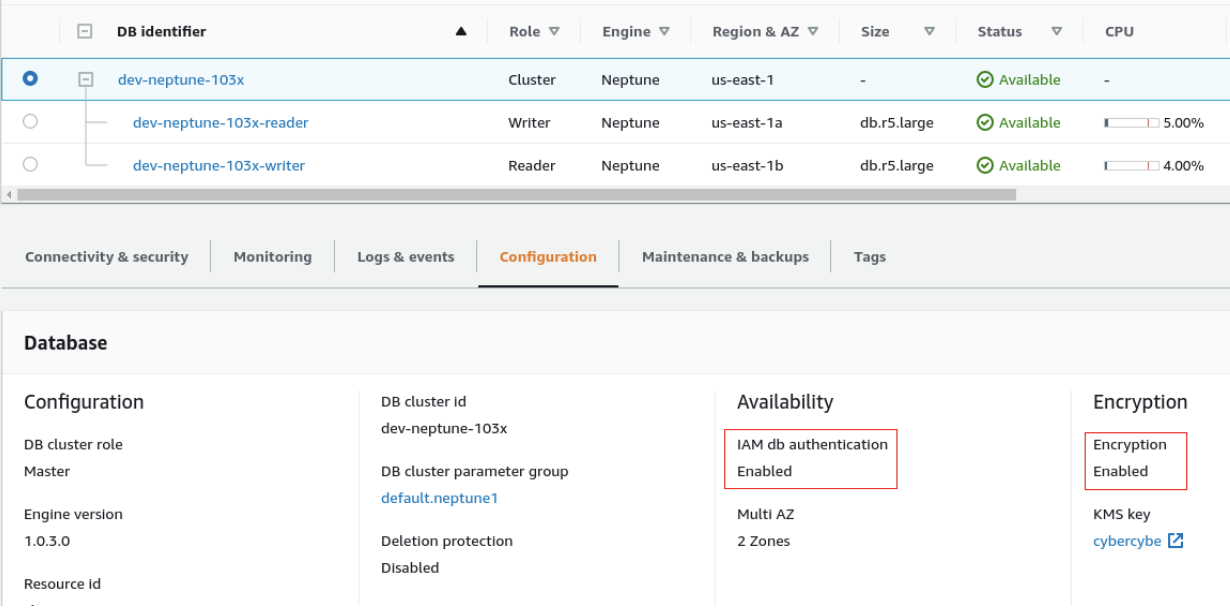
Note the IAM db authentication and Encryption being enabled.
There are several things that you will need to do in order to connect to the database from a Lambda function.
Add policies to the Lambda’s IAM role:

This policy will allow you to connect to the database, but since IAM authentication is enabled, you will need another policy:

The above policy allows your Lambda to assume a role that will have an access key and a token.
When setting up the security group for your Lambda function, you will need to add the Neptune port number: TCP 8182
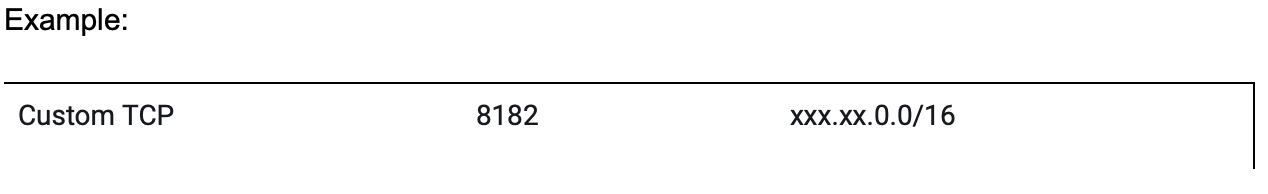
Connecting to Neptune from a Lambda function
Firstly, you will need a Gremlin module (in your package.json)

If IAM authentication is not enabled, the Gremlin is enough.
The gremlin-aws-sigv4 is a wrapper on top of Gremlin, and it allows you to connect to a Neptune instance that is secured with IAM.
You will need to assume a role:

The role ARN is stored as an environment variable (it’s the same role used for the Lambda function). The idea here is to obtain a session token, which will be used to authenticate with Neptune.


If the assumed Role is null, the function will connect to it without authentication (don’t try this at home kids!), otherwise, it will retrieve the credentials and session token from the assumed role and authenticate.
Once connected, the code will execute a simple query to ensure that the connection is valid.
let data = await connection.g.V().limit(1).count().next();
If this fails, an exception will be thrown and we can try to connect again.
Using Gremlin to talk to your Neptune Database
In my case, I use NodeJS to write my Lambda functions for the most part.
How do you check that an object exists?

You can use hasNext() to check that there is data available.
Here’s how you would insert a new Vertex into your database:

addV() will add a Vertex with whatever label you provide, in this case, it will be ‘group’. property() will add a property to your vertex.
The following will add a user to a group as long as that user is not already a part of the group:

Access Control
As we saw earlier in Exhibit 1, Vertices are linked together with Edges. A vertex can have a set of properties, as we saw in the code sample that adds a ‘group’ vertex (name of the group, type, etc).
Edges can also have properties. In our case, the SHARED_WITH edge has some properties that represent permissions. This means that when your application or UI retrieves the information for an object, it will be able to enforce some accessibility rules.
For instance, considering the following data:

The SHARED_WITH edge that links the current user to the owner contains properties that represent the permissions. In this case, the user can read the document, but not edit it, and she can share it with someone else.
Of course, if the user shares that document, she won’t be able to set permissions that she hasn’t been granted.
Gremlins!!!
I hope you’ve enjoyed this short guide to building relationships between users and assets using a graph database.
AWS Neptune is fairly easy to configure and use in a secure fashion. It also is fully integrated to the AWS ecosystem and allows you to implement solutions that would require a greater complexity if a Relational Database was used.
For more details about Gremlin you can check the following:
Tinkerpop Documentation official Gremlin/SparQL documentation
Practical Gremlin is an excellent book about Tinkerpop


